


Orbit is our pilot for a music discovery service that lets you find your next favourite song by exploring recently played tracks from ��ѿ��ý Introducing — the ��ѿ��ý’s platform for unsigned and undiscovered music. Every track is a crossroads where you have to decide with your ears: do you want to find out what you’re listening to, or do you want to try a related track? You can quickly move through the spectrum of musical genres, discovering what interests you and moving past what doesn’t. There’s no AI and no recommendation algorithms — you decide.
This article looks at how we organise music tracks behind the scenes to allow this kind of navigation. The other article in this series details the associated UX challenges.
A provocation
During a 6-month research project on young people and their music, podcast, and audio habits we found that they felt that music discovery was not intentional anymore: it just happened to them through algorithmic recommendations or, as they browse social media. As a response, we showed them a prototype where music played with no information — no image, no metadata — and they had to make choices based on what they heard using a joystick to go from track to track. It was a blunt instrument designed to get a reaction.
The reaction was very positive! Participants liked that it required them to trust their ears and pushed them out of their comfort zone. Their concern, however, was that it felt too random and they couldn’t quite get to something they liked reliably. For that prototype, we used 50 manually cut samples from the ��ѿ��ý Introducing database manually graded on them two aspects: how danceable the track is and how much singing there is in it. The directions weren’t labelled on purpose but it only made sense if you knew how it worked behind the scenes: it was hard to tell what each direction ‘meant’ just by listening because the organisation of the tracks was not granular enough.
For Orbit, we wanted to add more intentionality to the design: you should be able to go in a particular direction and feel it progressively get closer to your goal. More importantly, you should be able to feel it just from what you’re hearing. You can read more about the design work we’ve done in our other article.
In short, we needed a better way to organise the music to give sense of direction to the navigation that was also scalable to thousands of tracks.
"It feels really groundbreaking – an interesting way of discovering new music without feeling like you are discovering new music. Our local teams work so hard to find great tracks through the uploader, and it’s so exciting for new fans to be able to find what we’ve been playing in one space, based on what they like.”
Breaking down genres
Music is very often organised by genre — record shops have been organised this way for a long time. However, young people showed us that genres are less relevant to them today and artists seem to sit across genres more comfortably. Additionally, Spotify suggests that genres are now irrelevant to fans while organising their catalogue into . How many genres exist between well-known and well-understood genres like “rock” and “funk”? How would you decide?
Genres remain a useful shorthand to describe multiple aspects of a song. If someone says a track is ‘rock-y’ you can easily imagine that it has electric guitars (possibly distorted) and maybe sounds quite dark and aggressive. If someone says ‘folk-y’ you can see acoustic guitars and a sparser arrangement, something softer and more relaxed.
What if instead of breaking things down by genre, we could break down the genres themselves into component parts to start establishing a finer web of relationships between tracks? This way we could tell how close or far they are from each other sonically, exposing the complex overlap of genres.
Musical similarity
In his , Paul Arzelier shows how we can use mathematical distance between a series of musical descriptors to make more coherent playlists. The shorter the distance, the less difference there is between the tracks. Paul uses , his own open-source library, to extract several and features from an audio file and combines them to calculate the distance.
Though this was very promising, we had another hurdle to face: we didn’t want to make linear playlists but a multi-dimensional exploration tool with a feeling of direction. We wanted users to move based on what they heard: they have to feel the music become more or less ‘aggressive’ or ‘happy’ in a way they understood so they could follow their ears.
To get these more ‘human’ descriptors we used an open-source library called from the University of Barcelona. It provides machine learning models to extrapolate musical information from audio files (previously used in another project to analyse the Introducing database) such as danceability but also how aggressive, happy, sad or relaxed a track sounds.
With so many descriptors to choose from, picking only two as we’d done in the first prototype seemed as reductive as mashing them all into a single indicator. To strike a balance and still distribute the tracks on a 2D plane, we used a dimensionality reduction technique popular in data visualisation: a Principal Component Analysis (PCA).
Visualising connections
A PCA allows you to condense the most important information of a dataset by finding similarity between each data point based on their associated descriptors. In doing so, it compresses many of the descriptors into new ‘principal components’ which can be used as axes for a visual representation. As a result, each axis cannot be labelled easily as they now represent (‘explain’) many features at once.
We could pour all the descriptors we assembled from Essentia and Bliss into the PCA and obtain two axes to visualise our dataset. However, we needed a way to make sure that tracks were not just mathematically linked, but that their position made intuitive sense to a human going from track to track. Because the PCA looks for the strongest differences and decides how similar two tracks are based on this, the quality of these relationships entirely depends on the quality of the descriptors: do you have too many, the wrong ones or are they even accurate enough to group and separate tracks effectively?
So to make Orbit, we first built a tool that could change which features were going into the PCA and showed us the resulting plot. It also allowed us to play the tracks by clicking on points in the plot, meaning we could experience the similarity between the tracks with our own ears.
This method had a lot of potential but clearly we needed to fine-tune which descriptors went into the PCA to get a more successful organisation.

Orbit as a tool is potentially a huge boom for independent musicians and artists who are looking to promote their music. As an honest, unfiltered and transparent way of locating and discovering new music, it could be a huge resource for music lovers and potentially also AR and talent scout work.
Rebuilding genres
To know whether our new organisation was successful, we re-introduced genres into the plot by colour-coding each point using data extracted with Essentia. Now we could see if tracks from a similar genre were still roughly grouped together — because genres still represent the ‘compressed’ version of many descriptors — and we could see them appear as areas overlapping with each other, like a Venn diagram with interstitial pockets of micro-genres.
We reduced our 30+ descriptors to just eight ‘human’ ones: aggressive, danceable, electronic, happy, instrumental, party, relaxed, sad. Each track being rated from -1 (not at all) to 1 (very) on each of those. We tried various combinations until we could see some separation between opposed genres (e.g. classical vs dance) but see similarity between others (e.g.funk and hip-hop) while confirming by listening.
The final result makes sense to a computer but should also make sense to a human as they listen. With this list of adjectives, we can now describe tracks across genres and the PCA can position them into space.

Orbit is a great way of discovering new music and going down sonic rabbit holes to discover artists and genres that aren’t what you traditionally listen to.
Building the star field
The PCA gives us x/y coordinates for each track and we can use the distance between these points to determine their musical similarity — much like in Paul’s paper, but in two dimensions and with different indicators. However, for every single track, we need to establish which tracks they’re connected to.
We used a to find the closest neighbours for each point, regardless of distance. If a point is an outlier, the distance between two neighbouring tracks may be huge (and therefore their similarity low), but this is actually something we value to create doorways to new different genres. The resulting plot looked a lot like constellations in the night sky, so we dubbed the graph the ‘star field’.
At this point, we have all the data necessary to build a system that starts with a track and allows you to intuitively navigate based on the features we’ve chosen, at scale. The result is not perfect, but it’s all we needed to run our pilot with reasonable confidence. The last challenge is to automatically cut representative samples of the tracks that let users make quick decisions.
Audio thumbnails
Our first prototype used manually edited short snippets — less than 30 seconds that we thought were representative — to let users quickly decide about what they’re hearing. In our testing, users only needed a few seconds to choose between listening further or skipping. However, we need to do the artists justice with their work and choosing the ‘wrong’ sample would be unfair to them. Ideally, the artists themselves would select the most representative part of their track, however this wasn’t practical for the pilot as we’re re-using an existing infrastructure.
The process of finding and cutting that snippet is a well-known problem called audio thumbnailing. The is to find which part of the song is the chorus and use that, as it’s usually the most engaging part of the song. Traditionally we’d do this by finding the most ‘energetic’ part of the track — and the ��ѿ��ý even has an to do this. However, this method did not prove very accurate and didn’t scale well across genres in our testing.
Fortunately, recent advances in machine learning have made song structure analysis easier and we can now more reliably detect the chorus. We used an open-source library called to do this with . For songs that don’t have a chorus or where a chorus cannot be found (some electronic or folk music, for example), we trim any silence from the start and cut the first 20 seconds of the track.
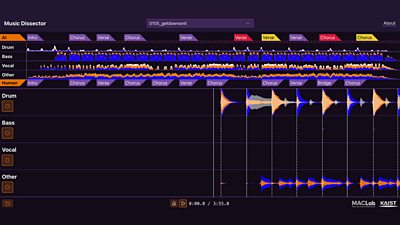
This has so much potential to be a really great thing for ��ѿ��ý Introducing artists AND for listeners. Artists are nothing without people to enjoy their work. It would be so great to one day hear things like - 'I found your music on Orbit! When is your next song coming out?'
Putting it all together
Consequently, we created an automated process using machine learning to cut and organise the tracks in an intuitive way. It facilitates organic discovery by reinforcing a sense of direction during exploration.
It’s notable that we’re doing this directly by looking at the track audio and no other external metadata. It doesn’t matter who listened to it or how much — it’s organised in relation to the other tracks in the dataset and how they sound.
By breaking down genres into a set of observable adjectives and rebuilding them on a 2D plane, we’ve created a more flexible and organic layout. Because ease of exploration was our priority, we found a different way to organise and discover music.
Orbit puts the users back in the driving seat, getting them to make conscious decisions about what they want to listen to rather than just taking what an algorithm feeds them. In doing so, it restores the feeling of ownership over musical discoveries and makes finding new tracks as fun and exciting as flipping through records in a bargain bin.
In the first 3 months of the trial, we had over 1 000 000 samples requested and it’s a very promising start. We’re now sharing the findings with our colleagues to see how best to take Orbit and its findings forward.
I found Orbit to be a great music discovery tool, not only did it help boost my own music but I found artists and tracks I love from it. In particular I found some great instrumental music, something that I struggle to come across normally as I never tend to branch out from my usual favourite genres.
More on Orbit
Part two of this series covers the design of the experience which gives users control of the music discovery process.
Search by Tag:
- Tagged with Content Formats Content Formats
- Tagged with Artificial Intelligence and Machine Learning Artificial Intelligence and Machine Learning
- Tagged with Audience Research Audience Research
- Tagged with Audio Audio
- Tagged with Content Discovery Content Discovery
- Tagged with Interactivity Interactivity
- Tagged with Recommendations Recommendations
- Tagged with User Interfaces User Interfaces
- Tagged with Features Features